Reinforcement Learning has proven to be capable of outperforming humans on various tasks by interacting with and experimenting some environment. This makes it one of the most interesting and promising AI solutions to problems that require complex behaviors which we are unable to fully define upfront but can assign an objective score to.
In many settings of interest such as in healthcare and finance, we’ll want to enforce safety constraints on any system of interest. Arguably, these settings are the most interesting since, when the stakes are the highest we’ll care most about the potentially adversary outcomes. Although RL has a lot to offer, it cannot be readily applied in such safety-critical settings due to its lacking guarantees on safety.
A recent line of work has proposed the application of formal methods to RL. These methods rely on logic and automated reasoning to prove that certain scenarios will never play out. They have been battle-tested in automated theorem proving as well as the verification of both hardware (e.g. chip design) and software (e.g. protocols and distribued systems).
By combining RL with formal methods, we obtain the best of both worlds: formal methods bring guarantees on safety under well understood computational characteristics while RL brings the adaptivity required for personalization in e.g. dialogue systems.
In a recent paper, we examined how the usage of formal methods impacts the learners' capability. We found:
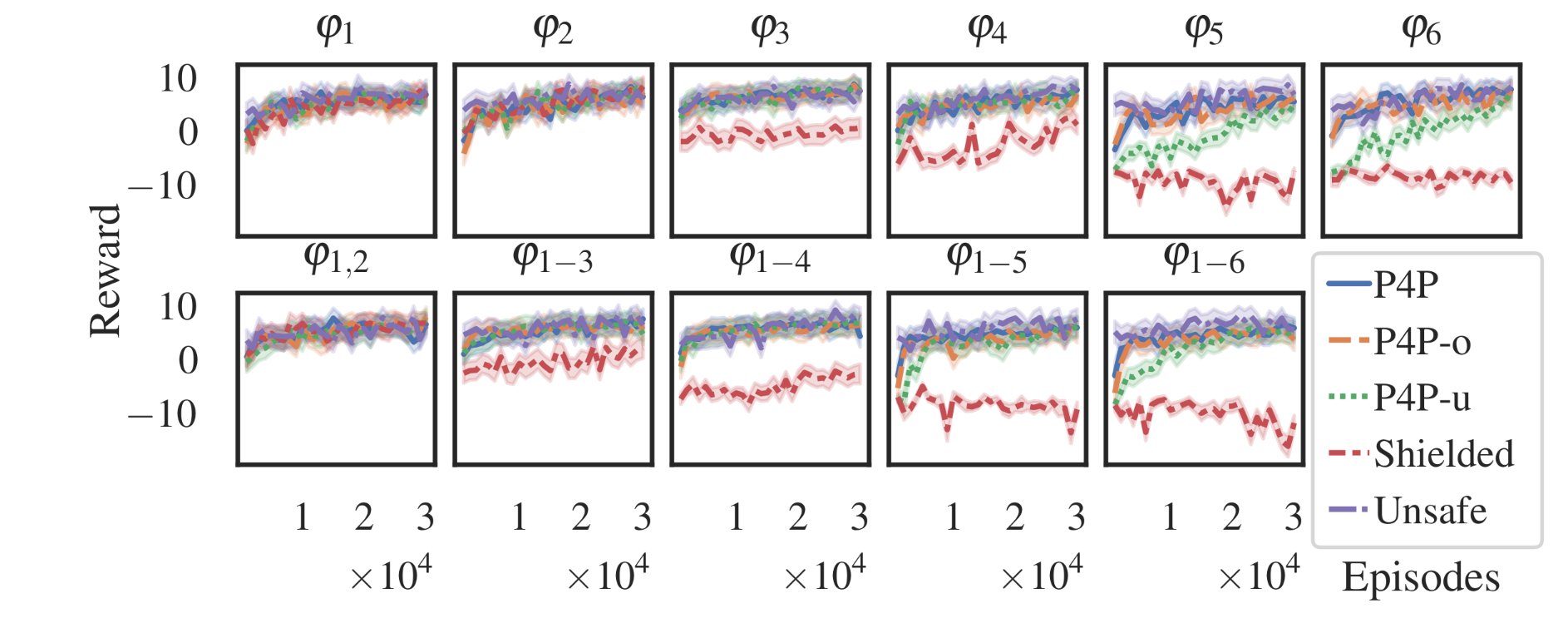
- that by applying safety constraints, the learning problem will generally become harder,
- that, if the safety constraints prescribe more steps at a particular state, the expected value for that state becomes lower
- that we can mitigate this by assigning an additional reward for steps taken to be safe, using a technique known as potential-based reward shaping
- that our proposed planning for potential (P4P) algorithm performs eliminates negative effects of the safety constraints, while remaining safe
- that we can tune its hyperparameter automatically by interacting with the environment
The paper detailing these ideas and findings can be found in Springer’s Machine Learning.
Update 2022-06-02: Accepted as extended abstract at IJCAI-ECAI-2022’s Workshop on Safe RL.
Update 2022-06-07: Presented as poster at BeNeRL 2022.