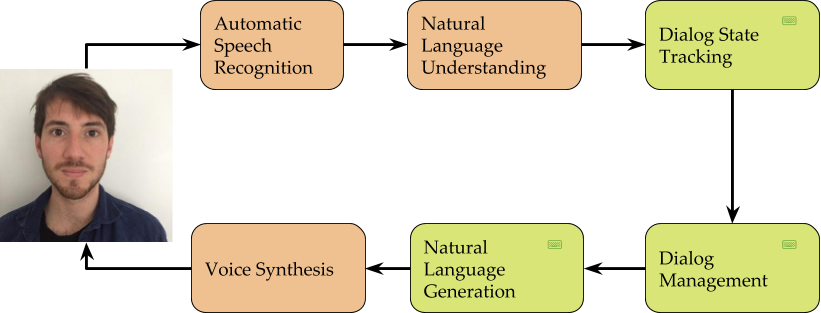
The value offering of most contemporary chatbot platforms consists of packaging state-of-art Automated Speech Recognition (ASR, or ‘speech-to-text’), Natural Language Understanding (NLU) and Voice Synthesis into a comprehensive API. The API typically also includes some programming model for dialog control such as DialogFlows' Contexts and follow-up Intents and Alexa’s Dialog model. Implementing the right dialog controller is up to the developer. Figure 1 summarizes this in a diagram, with the handcrafted modules in green and with a keyboard in the top right. These handcrafted modules Developers can use their experience and common sense or even turn to focus groups and A/B tests in optimizing these handcrafted parts of the bot. Although making all optimization decisions upfront works well in small systems, it fails to scale to applications where many decisions are involved such as when a personalized chatbot is desired. Reinforcement Learning (RL) can help in such cases. In this blog post, I’ll describe the formalism underlying most dialog management models, explain how this formalism can be generalized to support more flexible dialog management and finally, how RL can be used to optimize dialog management using data.
First, let’s consider the following dialog for ordering a drink at Marvin the Paranoid Android:

Marvin can serve tea in case a nonalcoholic beverage is preferred and can bring users that aren’t thirsty at the moment a towel. When the user doesn’t want any of this, they can end the interaction and leave Marvin to contemplate life. Finally, let’s assume that users don’t lie to Marvin about their preference for alcohol. We can formalize all of these possibilities as a finite state machine (FSM). First let’s have a look at a simple FSM for a turnstile.
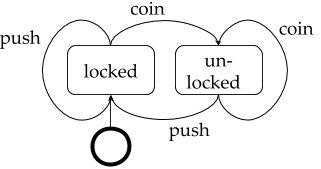
The FSM describes a system in terms of the states the system can be in and how all possible transitions affect the system. Transitions can be labelled, labels are typically referred to as input symbols as something external to the system provides these. In dialog, states are defined in terms of the available information in the system and transitions are formed by user inputs that have been processed by ASR/NLU. The developer specifies a system response for every state of the conversation. Adding an ‘end state’ for Marvin’s ordering system brings us to the following FSM, where transitions are labelled based on user inputs being positive (green) negative (red) or something else (blue):
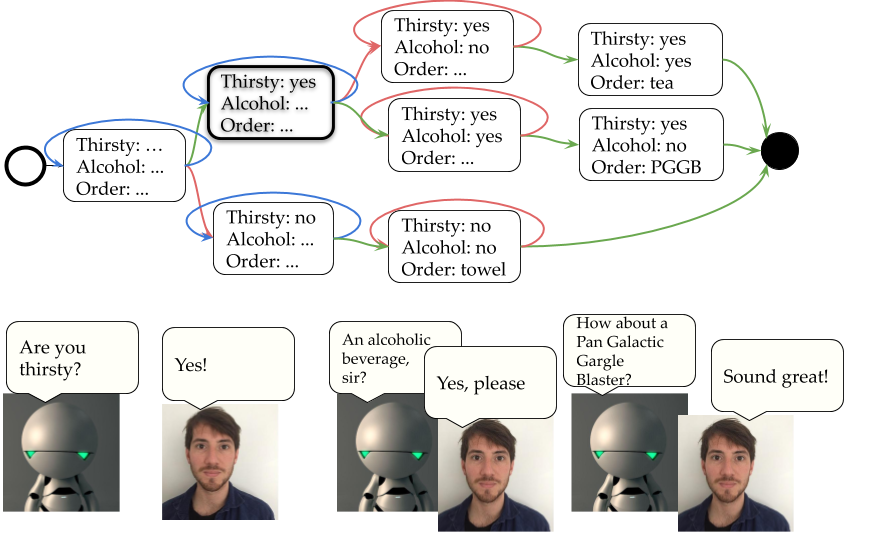
Now consider that users sometimes prefer a tea when they learn the only alcoholic option is a Pan-Galactic Gargle Blaster. Or that users want both a drink and a towel. These more complex scenarios require additional links and may require that the system utterances associated with some states are updated. What if we want the bot to respond differently for the highlighted node (bold lines) based on whether the system arrived following a green or blue transition? As system utterances are tied to dialog state, this requires splitting the node and defining utterances for both. How about taking into account that users will almost never want to order an alcoholic beverage at 9 AM and we could skip the suggestion for an alcoholic drink at such times? Or that a particular user is always thirsty? This requires different models for different users and at different times. Modelling all of this quickly becomes unfeasible, not only because of the number of decision to make but also because of the lack of any principled way of doing so. How about we see how actual users interacts with the system and use the resulting data to make the interaction better over time by learning what the system should say in which situation?
The first step for data driven dialog control is to decouple system utterances from states and maintain them in lists of system utterances \(A\) (for ‘action’) and system states \(S\). The transitions in the dialog system are no longer dictated by the system developer, but are given by users of the system. Some dialog state tracking (DST) algorithm1 can be used to determine the transition. Finally, some quality metric \(R\) for the chatbot to optimize should be defined (\(R\) for ‘reward’). Such a metric can be simply a combination of dialog length and success rate or more sophisticated models that estimate user satisfaction can be used. The goal of the chatbot now becomes to select the utterance \(a \in A\) given the current \(s \in S\) to maximize \(R\) for the entire conversation. This formalism is commonly referred to as the formalism of Markov Decision Processes (MDPs) and once the problem is in this shape, RL algorithms can be applied to optimize the dialogue controller using available data.
In practice, a generalization of MDPs in which part of the true state may not be observable are used in order to deal with ASR/NLU/DST errors and to be able to incorporate estimates of user intention in the dialog state. This generalization is referred to as a Partially Observable MDP (POMDP) and adds the notion of observations to the MDP. Stay tuned for more on POMDPs and RL algorithms!
Update: see this post if you’re interested in the usage of RL for personalization of the dialogue control